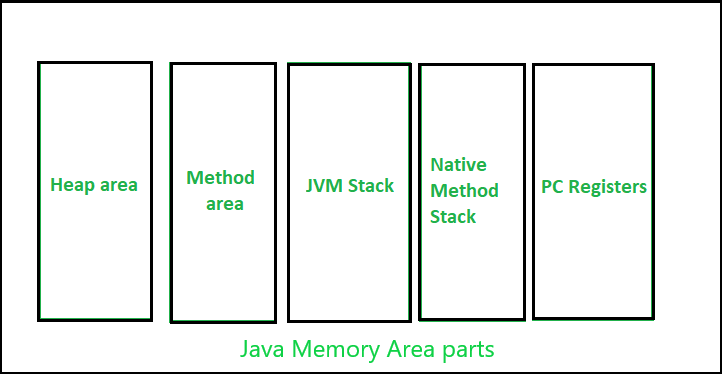
Data Migration goal is to enhance performance and competitiveness
Inexperienced execution causes more problems than solving it and also includes missing deadlines and exceeding budgets, incomplete plans this should be treated as a high priority
A strategic data migration plan should include consideration of these critical factors:
Knowing the data — Before migration, source data needs to undergo a complete audit. Unexpected issues can surface if this step is ignored.
Cleanup — Once you identify any issues with your source data, they must be resolved. This may require additional software tools and third-party resources because of the scale of the work.
Maintenance and protection — Data undergoes degradation after a period of time, making it unreliable. This means there must be controls in place to maintain data quality.
Governance — Tracking and reporting on data quality is important because it enables a better understanding of data integrity. The processes and tools used to produce this information should be highly usable and automate functions where possible.
In addition to a structured, step-by-step procedure, a data migration plan should include a process for bringing on the right software and tools for the project.
Data Migration Strategies
There is more than one way to build a data migration strategy. An organization’s specific business needs and requirements will help establish what’s most appropriate. However, most strategies fall into one of two categories: “big bang” or “trickle.”
“Big Bang” Migration
In a big bang data migration, the full transfer is completed within a limited window of time.
Live systems experience downtime while data goes through ETL processing and transitions to the new database.
The drawback of this method is, of course, that it all happens in one time-boxed event, requiring relatively little time to complete. The pressure, though, can be intense, as the business operates with one of its resources offline. This risks compromised implementation.
If the big bang approach makes the most sense for your business, consider running through the migration process before the actual event.
“Trickle” Migration
Trickle migrations, in contrast, complete the migration process in phases. During implementation, the old system and the new are run in parallel, which eliminates downtime or operational interruptions. Processes running in real-time can keep data continuously migrating.
Compared to the big bang approach, these implementations can be fairly complex in design. However, the added complexity — if done right — usually reduces risks, rather than adding them.
Best Practices for Data Migration
Regardless of which implementation method you follow, there are some best practices to keep in mind:
Back up the data before executing.
In case something goes wrong during the implementation, you can’t afford to lose data. Make sure there are backup resources and that they’ve been tested before you proceed.
Stick to the strategy.
Too many data managers make a plan and then abandon it when the process goes “too” smoothly or when things get out of hand. The migration process can be complicated and even frustrating at times, so prepare for that reality and then stick to the plan.
Test, test, test.
During the planning and design phases, and throughout implementation and maintenance, test the data migration to make sure you will eventually achieve the desired outcome.
6 Key Steps in a Data Migration Strategy
Each strategy will vary in the specifics, based on the organization’s needs and goals, but generally, a data migration plan should follow a common, recognizable pattern.
1. Explore and Assess the Source
Before migrating data, you must know (and understand) what you’re migrating, as well as how it fits within the target system. Understand how much data is pulling over and what that data looks like.
There may be data with lots of fields, some of which won’t need to be mapped to the target system.
There may also be missing data fields within a source that will need to pull from another location to fill a gap. Ask yourself what needs to migrate over, what can be left behind, and what might be missing.
Beyond meeting the requirements for data fields to be transferred, run an audit on the actual data contained within. If there are poorly populated fields, a lot of incomplete data pieces, inaccuracies, or other problems, you may reconsider whether you really need to go through the process of migrating that data in the first place.
If an organization skips this source review step, and assumes an understanding of the data, the result could be wasted time and money on migration. Worse, the organization could run into a critical flaw in the data mapping that halts any progress in its tracks.
2. Define and Design the Migration
The design phase is where organizations define the type of migration to take on — big bang or trickle. This also involves drawing out the technical architecture of the solution and detailing the migration processes.
Considering the design, the data to be pulled over, and the target system, you can begin to define timelines and any project concerns. By the end of this step, the whole project should be documented.
During planning, it’s important to consider security plans for the data. Any data that needs to be protected should have protection threaded throughout the plan.
3. Build the Migration Solution
It can be tempting to approach migration with a “just enough” development approach. However, since you will only undergo the implementation one time, it’s crucial to get it right. A common tactic is to break the data into subsets and build out one category at a time, followed by a test. If an organization is working on a particularly large migration, it might make sense to build and test in parallel.
4. Conduct a Live Test
The testing process isn’t over after testing the code during the build phase. It’s important to test the data migration design with real data to ensure the accuracy of the implementation and completeness of the application.
5. Flipping the Switch
After final testing, implementation can proceed, using the style defined in the plan.
6. Audit
Once the implementation has gone live, set up a system to audit the data in order to ensure the accuracy of the migration.
7. Data Migration Software
Building out data migration tools from scratch, and coding them by hand, is challenging and incredibly time-consuming. Data tools that simplify migration are more efficient and cost-effective.
When you start your search for a software solution, look for these factors in a vendor:
Connectivity — Does the solution support the systems and software you currently use?
Scalability — What are the data limits for the software, and will data needs to exceed them in the foreseeable future?
Security — Take time investigating a software platform’s security measures. You’re data is one of your most valuable resources, and it must remain protected.
Speed — How quickly can processing occur on the platform?